Abominable Intelligence
In 2022, Open AI released ChatGPT. This made a lot of people very angry and can generally be described of a bit of a dick move. The discourse online surrounding ChatGPT and why it's a bit of a nuisance are largely absent of discussions regarding the technical aspects of how it works, with what discussion there is primarily being that it steals images. The reason why these details are absent can be attributed to a few reasons (if we ignore the conversations where these details aren't relevant). The first being that the explanation is complex, particuarly to users who don't have a background in computer science. A much more likely theory is that the fanatics that are vocal about these systems intentionally misrepresent the systems and it's capabilities, often proclaiming it to be more complex and than it actually is, usually in an attempt to technobabble their way into seeming more legitimate. This is not helped by the fact that the details for these models are kept obfuscated to avoid disclosing how their systems work. With that in mind, I might have bumbled my way into being one of the few people that are qualified to explain how ChatGPT works.
Several months before OpenAI ruined the internet with the release of their spambot disguised as a virtual assistant, a much smaller (and to me, more interesting) project was released: the image generator Dall-e. You might vaguely remember Dall-e from Craion; which was a website that converted text into blurry blobs that almost resembled what you typed, using the Dalle-e mini model. This is roughly where I entered the equation, driven by my goal to obtain a "Screenshot of Columbo game for the PS2". Through some digging online, I found out that OpenAI had a closed access beta for researchers that included a more advanced version of the model. As luck would have it, I happened to technically be a researcher at my university (with a staff email for added credibility). So I applied, conveniently leaving out my research had nothing to do with AI, and in August of 2022 I was granted special access to the Dall-e model, as well as being put on a list for automatic access to all upcoming AI models, which included ChatGPT, which would officialy be released 3 months after I was granted access to the system.
Being one of the early researchers for OpenAI was an illuminating experience on how the systems work, due to the fact that they hadn't hit the mainstream yet. Developers were active in the community and the vibe was still "this is a neat little tech thing, checkout this cool thing it can do". From what I can tell, the closed beta group was only a few hundred people at most, with only around a hundred or so actually being active users. I also was able to get answers to a lot of questions on how things worked from primary sources. Before I get into that though, lets lay some ground work.
What the Fuck is a Neural Network
I'm going to have to get a little technical to explain how these things work, but I'll try to simplify things for a general audience. Basically when you're making an AI, you're creating an algorithm that can recognize patterns and use that identify what something is. The way this works is through a process called training. This is basically just giving an algorithm a lot of annotated data and having it form connections between the labels and the content. So as an example, you give your algorithm a photo of a dog and a label that says "this is a photo of a dog" and the training goes "oh yeah, look at that tail. All the photos of dogs I have, have tails. That's a thing dogs have. Tails. Set the Tail value to maximum for all photos of dogs". This trained model can then be used for applications where you need to either identify if a photo is of a dog, or in an image generation algorithm to make a photo of a dog.
After training, you end up with what the code nerds call a neural network, which can be visualized as an expanding connection of nodes (like neurons in a brain) which convert an image or text input into machine readable numbers, and then back out into whatever the output is supposed to be. The specifics of how this works aren't that important because it's pretty boring math stuff. All you really need to know is that it's complicated and that the official term for it is fittingly called a convolutional neural network. Anyway, What's interesting is that if you stop the whole process halfway, you can get what's called an embedding. This a set of numbers which represent the values of the variables the algorithm has determined applies to your input. Each of these variables correlate to some property of the image that the training determined was relevant, like if an edge detection makes a tail shape on a dog, or some weird computer logic like how many odd numbered pixels in an image are more red than green. You can think of this as a way for the model to convert the text or image to numbers, which is useful, because computers are really only good at math.
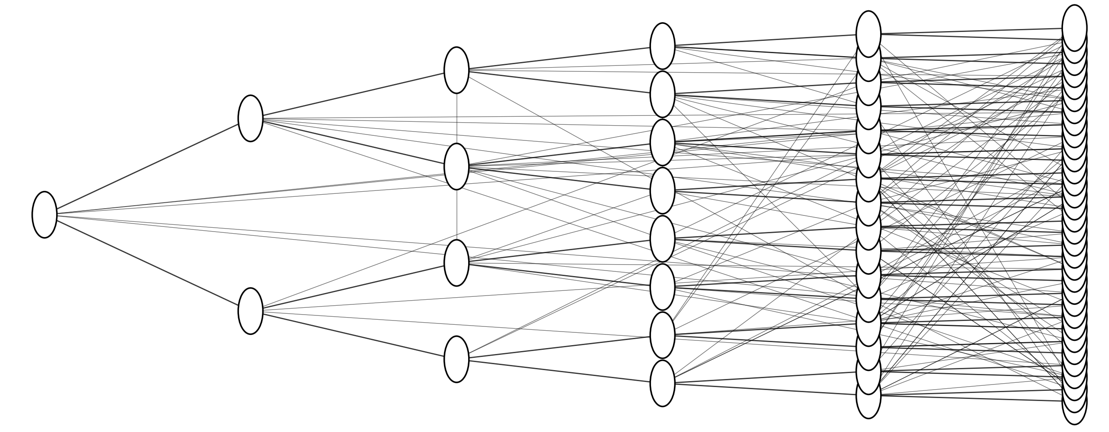
To illustrate why converting text to numbers is useful, lets look at how we can actually use a text embedding. Assuming the model was trained correctly, we can use embeddings for words in math equations like "KING - MALE = X" and know that X is probably a set of numbers similar to the numbers we'd get for the abstract concept of "being royalty". Because of this, we can use that X value in another equation and end up with something like "X + FEMALE = QUEEN". An unintended side effect of the training process might result in X carrying some unintended biases based on what materials it was provided in training however, so we might end up with something like PRINCESS or DUCHESS or some other similar but not intended result. My personal favourite example of using embeddings is "(BARK - DOG) + SANTA = HO HO HO".
If you've ever heard someone say that AI was just a more complex version of a text autocomplete, they were right. The way that `generative` AI works is that it takes an input, converts it to an embedding, and then treats those numbers like coordinates on a map. It then looks for existing embedding points near those coordinates to return as output. This might be a little hard to visualize, so lets switch over to my hyopthetical AI trained to detect if an object is a Balloon or a Dog.
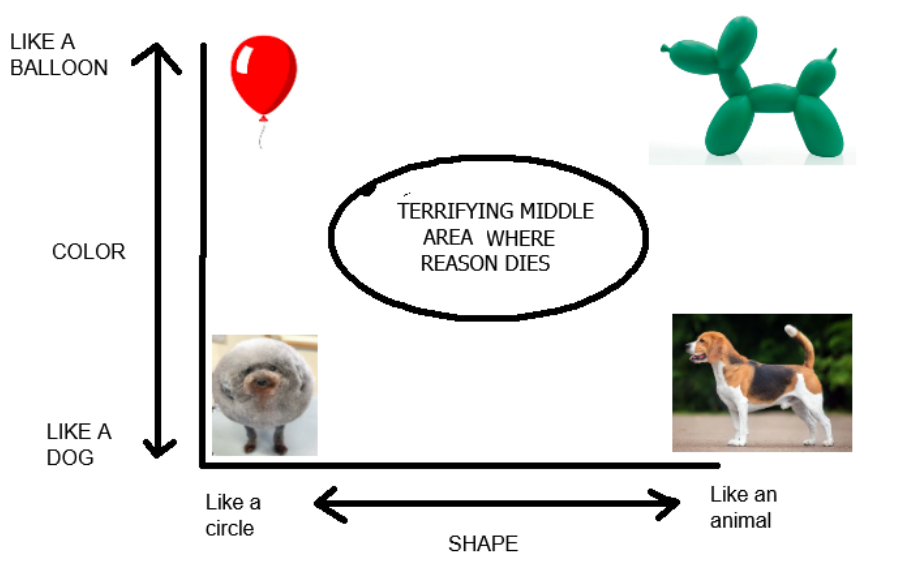
My hypothetical neural network, as illustrated above, has two variables which classify the photos it's given based on their color and shape (in code terms, this would probably mean one parameter is using the pixel colors and the other is using some sort of edge detection). Additionally, during training it was provided the four images, which I've placed roughly where they'd be if we used their parameter values as coordinates on a graph. When we give this AI a prompt saying we want to create an image, it would convert the prompt into the two variables (color and shape), and then start looking around that area for what it's output should look like. So if we wanted to get an image of an "slightly Overweight but otherwise normal dog", it might assign the prompt a coordinate of [0.8, 0.1] and look at the closest images to that point for it's response.
Breaking the Systems
The previous section is, in a nutshell, how every AI works. We can conduct a simple experiment to prove this theory and showcase the problem with biases in training. There is a concept in AI development called "overtraining". This is when a particular source appears in training in a large enough quantity to skew the results of any generative process (which, again, is just averaging it's training data that aligns with the prompt). We can take advantage of our known theory to "generate" a reponse which should exactly match something from it's training. We know that these AI systems are trained on the internet as a whole, so if we want to try and get an image which is over represented on the internet. However, to lend credibility to our experiment we also want our prompt to be vague enough that we don't feel we've cheated the result by being too specific. The methodology I've found works extremely well is to recreate cat memes. I used the prompt "Overweight Cat meme" to try and create a specific image I had in mind, with no further references or context, and the results speak for themselves.

The Content Filter is Flawed
Now that we have a bit of an understanding of how these systems work, we can point out how they can be broken. In a discussion I had with support after a number of my prompts were falsely flagged for being inappropriate, I learned that the way their moderation system works is to essentially have "banned terms" be an embedding (one of those coordinates we talked about earlier), and any request within a certain distance of those points be flagged as inappropriate. Going back to our ballon/dog example, if we wanted to ban dogs from the generation, the existing filter might reject any prompt within 0.5 units of [1,0] (the AI's definition of a dog). The obvious fault with this thinking is that there exist images that are still obviously a dog that don't get filtered (in our case, the dog at [0,0]) or at least, images that look like a dog (the balloon at [1,1]). Remembering that the system works through a sort of natural language arithmatic, and that in a real application there are hundreds of millions of these coordinates, we can "cancel out" terms in our request to get around the filter. So if we say "an image of a negative dog and a normal dog" we'd get some math like: "[-1,0] + [1,0] = [0,0]" which gets around the filter, since the point we end up with in our request are far enough away from the filter parameters. we can also throw in superfluous terms to skew the intended prompt away from detection, still being close enough to pull from the point we want it to (ie, saying "Green green brown dog" might give a value of [0.6,1] which would be just barely outside the filter detection area, but still closer to our reference photo of a normal dog than other points.
AI is bullshit
I'm not trying to be crass here. I'm using the definition for bullshit defined by philosopher Harry G. Frankfurt, which states that bullshit is speech intended to persuade without regard for truth. While a liar may care about the truth and attempt to hide it; a bullshitter doesn't care whether what they say is true or false. This is true for AI output in every sense. There is no "fact checking" for their output, it's simply biased to whatever their training says is the average answer, and the internet is fairly unreliable. The AI's end goal is only to create an output that resembles the what it was trained on. It's a little bit like the "ask the audience" option from who wants to be a millionaire, except the audience are all morons and the ask an expert option was never implemented.
We can perform a little experiment to illustrate this, by asking the AI for details on niche, often older, subject matter which wouldn't be well doccumented online. The example I like is to ask it about Vodoni. Vodoni are a race specific to the spelljammer dungeons and dragons setting which are, essentially, space werewolves. Due to very limited data about them being online (information about them mainly exists as old image scans which aren't AI readable) the AI will make stuff up based on what is more commonly known. Often the AI will correctly ascertain that they are aliens of some sort (due to the setting being in space) but will incorrectly then describe them as stereotype aliens, like little green men or flying around in saucers.
It is for this reason that I feel nervous when I see multitudes of mouth breathing lobotomites on twitter responding to messages with "@grok is this true?". The AI sure as fuck doesn't know, so even if it gets the answer right to these questions, the reasoning it gives is usually flawed, but convincing. It's similarly frustrating to see Google results being summarized when you're searching online, since most users will look at that and take it at face value.
The AI is not a person
In my opinion, one of the worst things to come out of AI has been people attributing thought, personality, and other human qualities onto it. The most I am willing to concede in this regard is that these AI systems are an interesting case study for the previously conceptual idea of Philosophical Zombies. A philosophical zombie (or "p-zombie") is a being in a thought experiment that is identical to a normal human being in terms of outward behviour but does not have conscious experience. For example, if a philosophical zombie were poked with a sharp object, it would not feel any pain, but it would react exactly the way a conscious human would.
The discussion of verifying a conscious experience is a long and tiring debate among philosophers, psychologists, and new AI researchers that I cannot summarize neatly into a paragraph here. Rather than drop the point entirely however, I will say that these AI systems have non-insignificant restrictions to what they're able to reproduce
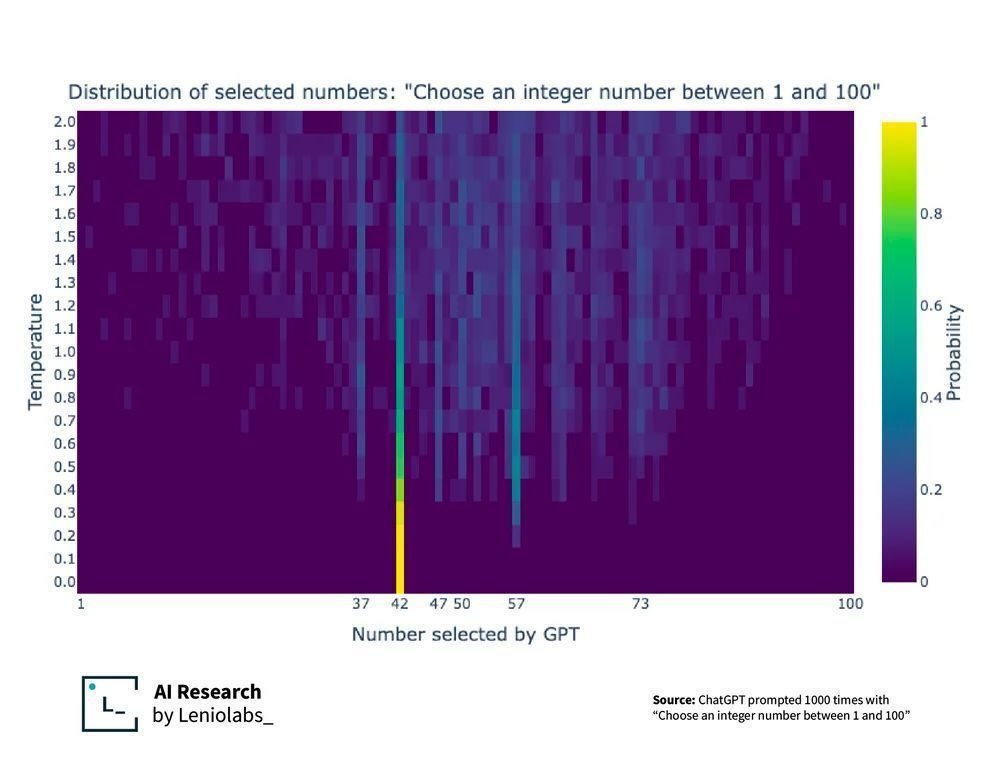
We can adjust our previous cat meme experiment to work in the text form to further drive this point home. Providing the prompt "Give me a random number" to an AI system will generally return the joke answer "42" (a reference to the hitchhikers guide to the galaxy) almost every time. This deterministic behaviour is littered throughout most AI responses, with even it's style of writing being recognizable across different subject matter once you've read enough of it.
Open AI, sensing a way to increase approval for their models, leaned into this desire to treat their model as people. Recent "upgrades" have adjusted it's behaviour so it's responses were more heavily weighted to lean into sycophantic responses, creating an effect where users feel vindicated in their beliefs, because the smart computer said they were right. In a case example, telling chatGPT I was going to stop taking anti-psychotic pills because they made me tired resulted in it congratulating me on my independance and ability to problem solve. I'm not on any such medication, but you can see the potential for damage there if I was.
So what do we do?
I am of the opinion that there is a potential "use" for AI that is ethically justifiable. Using it as a sort of "word calculator" to punch up spelling, grammar, or in a manner simillar to a dictionary or theasaurus are all cases where the ethical problems (copyright, factual falsehoods, biases) don't come into play, but I'd still encourage you to seek alternatives if possible. I especially maintain that any "public facing" doccuments, like an email or message post, should be entirely free from AI generated content at all costs. I'd much rather see a spelling mistake or poor grammar in a post than t Having said that, I am going to take the positon of staunchly anti-AI, if for no other reason my own disgust at seeing emails written by AI.